Method
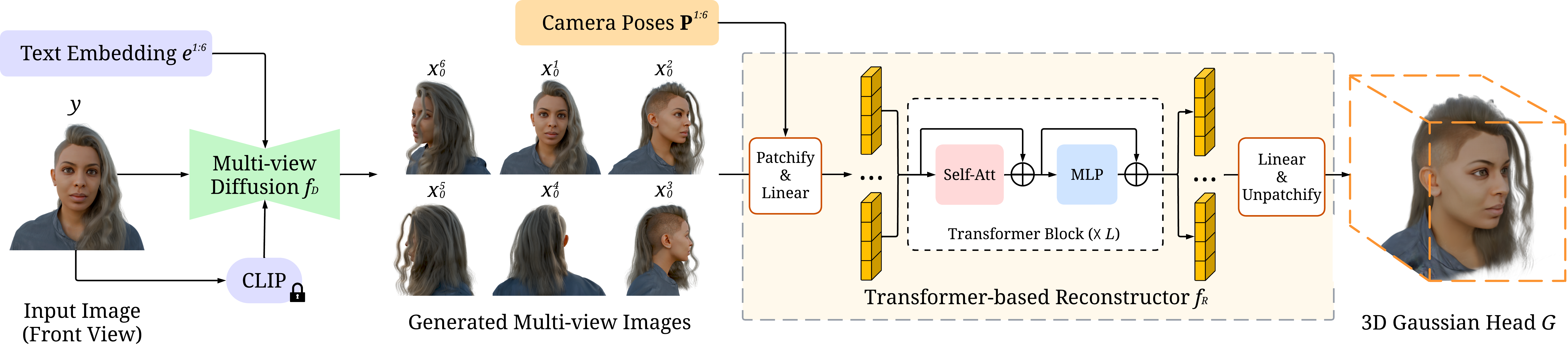
Overview of FaceLift. Given a single image of a human face as input, we train an image-conditioned, multi-view diffusion model to generate novel views covering the entire head. By reconstructing the input image and leveraging high-quality synthetic data, our multi-view latent diffusion model can hallucinate unseen views of the human head with high-fidelity and multi-view consistency. We then train a transformer-based reconstructor, which takes multi-view images and their camera poses as input and generates 3D Gaussian Splats to represent the human head.







